

Traditionally, SAP is populated with Master Data with no real consideration of future reliability improvement. Only once that maintenance is actually being executed does the real pressure of any under performing assets drive the consideration of the reliability strategy. At that point the mechanics of what’s required for ongoing reliability improvement, based upon the SAP Master Data structure, is exposed and, quite typically, almost unviable.
The EAM system is meant to support reliability. Getting your EAM system to support reliability requires some firm understanding of what must happen. If we look a little closer at reliability and the phases of life of an asset, we can see why the EAM settings must vary and not be fixed.
The initial reliability performance of any system is actually determined by its design and component selection.
This is probably not a big surprise for anyone close to reliability, but it may spark some debate from those who have not heard this before.
As evidence to support this statement, a newly commissioned and debugged system should operate nearly failure free for an initial period of time and only become affected by chance failures on some components. An even closer inspection can show that during this period, we can expect that most wear out failures would be absent after a new machine or system is placed into service. During this “honeymoon period” preventative replacement is actually not necessary nor would an inspection strategy provide benefit until such time as wear (or unpredictable wear) raises the possibility of a failure. Within this honeymoon period the components of the system behave exponentially and fail due to their individual chance failures only. They should only be replaced if they actually fail and not because of some schedule. Minor lubrication or service might be required, but during this initial period, the system is predominantly maintenance free and largely free from failure.
Here is where the first hurdle occurs.
After the initial period of service has passed, then it is reasonable to expect both predictable and unpredictable forms of wear out failures to gradually occur and increase in rate, as more components reach their first wear out time.
If repair maintenance (fixing failures) is the only strategy practiced, then the system failure rate would be driven by the sporadic arrivals of the component wear out failures, which will predictably rise rather drastically, then fluctuate wildly resulting in “good” days followed by “bad” days. The system failure rate driven by component wear out failures, would finally settle to a comparatively high random failure rate, predominantly caused by the wear out of components then occurring in an asynchronous manner.
With a practice heavily dependent upon repair maintenance, the strength of the storeroom becomes critical, as it makes or breaks the system availability which can only be maintained by fast and efficient firefighting repairs. The speed at which corrective repairs can be actioned and the logistical delays encountered, drive the system availability performance.
From this environment, “maintenance heroes” are born.
As the initial honeymoon period passes, the overall reliability the system becomes a function of the maintenance policy, i.e. the overhaul, parts replacement, and inspection schedules.
The primary role of the EAM is to manage these schedules.
The reduction or elimination of predictable failures is meant to be managed through preventative maintenance tasks, housed inside the EAM that counter wear out failures. Scheduled inspections help to counter the unpredictable failure patterns of other components.
If the EAM is properly configured for reliability, there is a tremendous difference in the reliability of a system. The system reliability becomes a function of whether or not preventative maintenance is practiced or “only run to failure then repair” maintenance is practiced. As a hint: the industry wide belief is that some form of preventative practice is better than none at all.
Preventative maintenance is defined as the practice that prevents the wear failure by preemptively replacing, discarding or performing an overhaul to “prevent” failure. For long life systems the concept revolves around making a minimal repair that is made by replacement of the failed component, and resulting in the system then restored to service in “like new” condition. Repair maintenance was defined as a strategy that waits until the component in the system fails during the system’s operation.
If the EAM is not programmed correctly or if the preventative tasks are not actioned, then the reliability of a system can fall to ridiculously low levels, where random failures of components of the recoverable system, plague the performance and start the death spiral into full reactive maintenance.
This is quite costly, as in order to be marginally effective the additional requirement is a fully stocked storeroom, which raises the inventory carry costs. Without a well-stocked storeroom, there are additional logistical delays associated with each component, that are additive in their impact on the system availability, and the system uptime, and so system availability becomes a function of spare parts.
An ounce of prevention goes a long way.
Perhaps everything should be put on a PM schedule? This is actually the old school approach, and I find it still exists in practice all over the world.
The reliability of a system is an unknown hazard and is affected by the relative timing of the preventative task. This timing comes from the EAM in the form of a work order which is supposed to be generated relative to the wear out of the component. How well this task aligns with reality is quite important. If the preventative work order produced by the EAM system comes out at the wrong time, there is a direct adverse effect on system reliability.
EAM systems are particularly good at forecasting the due date of the next work order and creating a work order to combat a component wear out failure. However, wear is not always easily predicted by the EAM and so we see in practice, that not all EAM generated work orders suppress the wear out failures. One reason for this variance is the EAM system work order was produced based on the system calendar time base along with a programmed periodicity that was established in the past to predict the future wear performance.
We don’t always get this right.
As a result we generate work orders for work that is not required, or work that should have been performed before the component failed, not just after the component failed.
Maybe this sounds familiar?
Calendar based forecasts assume wear is constant with time. It is not.
A metric based in operating hours is often a more complete and precise predictor of a future failure. It’s true most EAM systems today allow predictable work to be actioned and released by either calendar time or operating hours and allow other types of time-indexed counters to trigger PM work orders.
A key to success is producing the work order just ahead of the period of increased risk to failure due to wear. Whether by calendar or some other counter we call the anticipation of failure, and the work order to combat it, the traditional view of maintenance.
This all sounds simple enough.
The basic job of a reliability engineer is to figure out when something will likely fail based on its past performance and schedule a repair or part change. The EAM functionality is used to produce a work order ahead of the failure, and if that work is performed on-time, we should then operate the system with high reliability.
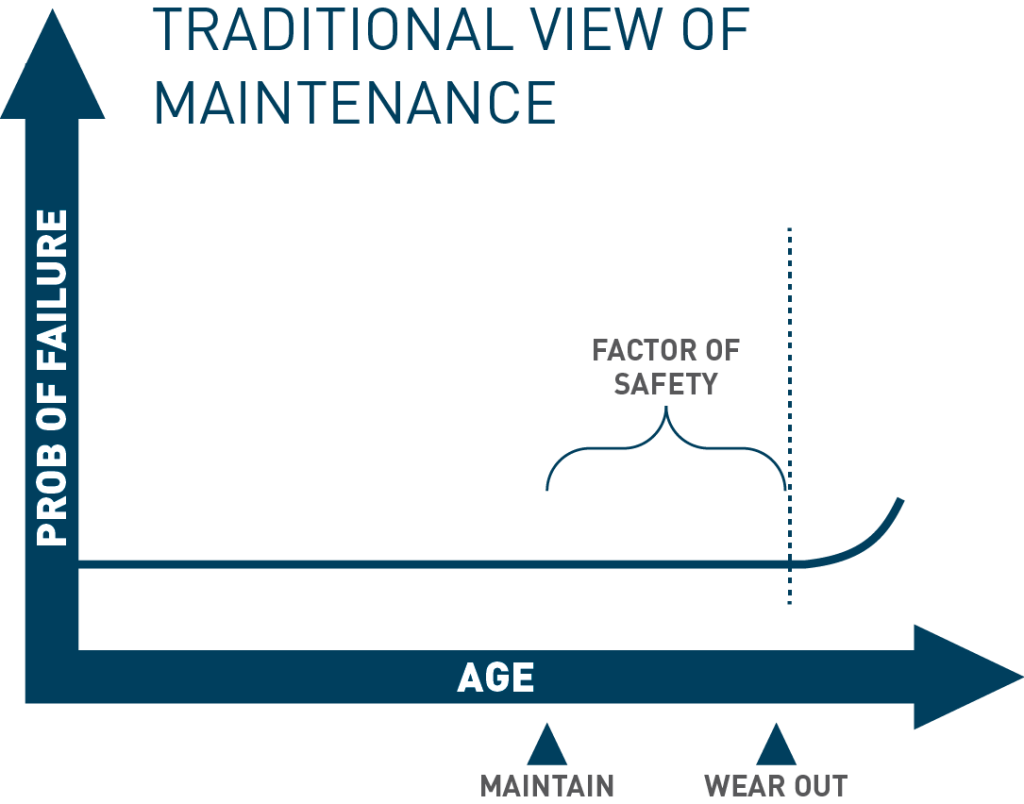
The reliability side of this conjecture, when combined with an EAM to support, is problematic.
If the work order is either ill-timed from the EAM or not performed on time during the maintenance work execution, there is an increased finite probability that the preventative task will not succeed in its purpose to prevent a failure. Equally devastating, if the PM schedule is poorly aligned or poorly actioned, the general result mirrors the performance expected from a repair maintenance policy, and the system can decay into a ridiculously low level of reliability, with near constant sporadic wear out of one of the many components within the system.
When preventative maintenance is properly practiced so that it embraces all components known to be subject to wear out, a repairable system can operate at high reliability and availability with a very low “pure chance” failure rate and do so for indefinitely long periods of time.
Determining what to put into the EAM is really where the game begins.
